Showcase · Case studyPowered by B-roll 科学讲解
The full creative process
从最初需求到最终成品,共 5 个章节。
01/ 05
05-14 03:40
确定选题:从植物转向蜥蜴
U
User brief
你有和植物相关的题材吗?……那蜥蜴的怎么样?
R
What Ribbi did
该 Skill 主动按方向给出了一组可选主题,帮助用户迅速从植物切换到蜥蜴,并进一步收敛到最有视觉表现力的点子:“变色龙为什么会变色”。
02/ 05
05-14 03:42
确认时长并生成脚本
U
User brief
就做变色龙变色吧,做成 60 秒
R
What Ribbi did
用户把时长从 2 分钟改成了 60 秒,Skill 立即将配音稿压缩到约 195 个中文字符,同时保留了“三段式”结构:“反直觉钩子 → 机制解释 → 结尾洞见”,然后等待用户确认。
03/ 05
05-14 03:48
生成 TTS 解说音频
U
User brief
看起来不错
R
What Ribbi did
用户只用这一句确认,Skill 就自动生成了一段 67 秒的中文科学解说音频,并同步产出带时间戳的字幕文件,为后续叠加视觉信息卡打好了基础。

变色龙变色科普旁白音频
0:00
1:07
04/ 05
05-14 03:57
规划并预览视觉信息卡
U
User brief
让我看看你还能加什么……像 “a few hundred nm” 这种中英混排看着有点怪,再加一张开场卡
R
What Ribbi did
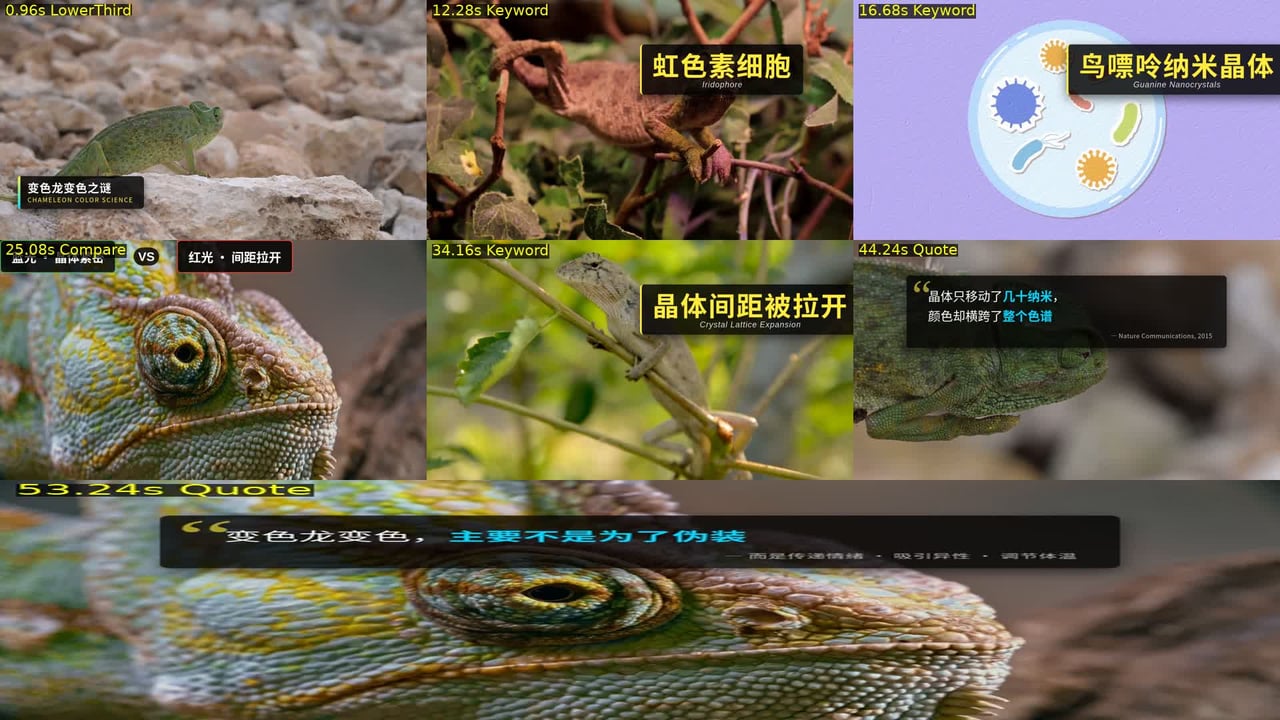
Skill 读取了字幕时间轴,规划出 7 个信息卡提示点(LowerThird 简介、关键词、对比、引用)。它把不太适合可视化呈现的中文数字表述替换成概念卡,然后抓取关键帧、叠加渲染结果,并拼成 3x3 预览网格,方便用户检查位置和文案。
05/ 05
Approved
05-14 04:04
最终渲染与视频合成
U
User brief
开始渲染吧
R
What Ribbi did
方案确认后,Skill 并行渲染了 7 张动态卡片,再用 ffmpeg 逐一叠加到视频上,烧录字幕,最终导出成片:一支 67 秒横版科学视频,画面中的信息节奏与解说同步推进。
Why it works
5 条原因,每一轮都能落地。
01 · 只给一个主题,AI 就能完成资料研究
用户只需要提供一个关键词。随后 Skill 会同时从多个来源提取核心科学知识,并提炼成适合可视化表达的概念,无需用户自己准备素材或撰写文案。
02 · 脚本结构自带钩子与节奏
配音稿会被自动整理成“三段式”结构:“反直觉钩子 → 机制解释 → 结尾洞见”,语气自然口语化,并能适配从 60 秒到 5 分钟的不同视频时长。
03 · TTS 配音会自动匹配内容风格
Skill 会根据内容风格,在纪录片语气和科普创作者语气之间自动选择合适的人声与语速。中文和英文也都会匹配对应声音,无需手动挑选。
04 · 字幕同步生成,并支持迭代校对
TTS 完成后,Skill 会同步输出带时间戳的字幕文件。它还可以校对错别字并清理标点,让字幕始终与解说精准对齐。
05 · 信息卡会按内容定制,并自动叠加到视频中
针对脚本中的关键概念与数据点,Skill 会规划关键词卡、对比卡、LowerThird 等动态信息卡。在逐帧预览确认后,它会通过 ffmpeg 将这些卡片叠加到视频中并烧录字幕,让画面信息密度与解说节奏保持一致。
